Dans ce tutoriel, je vais vous montrer comment exploiter la nouvelle fonctionnalité révolutionnaire d'Excel 2025 : l'intégration directe de Python !
Cette innovation va transformer radicalement votre façon d'analyser des données et de créer des visualisations professionnelles.
Que vous soyez un utilisateur novice ou expérimenté d'Excel, vous découvrirez comment quelques lignes de code Python peuvent remplacer des heures de manipulations fastidieuses et vous permettre d'obtenir des indicateurs précieux en un temps record.
Nous allons explorer ensemble, étape par étape, comment charger vos données Excel dans Python, réaliser des analyses statistiques avancées, et créer des visualisations percutantes sans jamais quitter votre environnement Excel familier.
Téléchargement
Vous pouvez télécharger le fichier d'exemple de cet article en cliquant sur le lien suivant :
Tutoriel Vidéo
1. Présentation
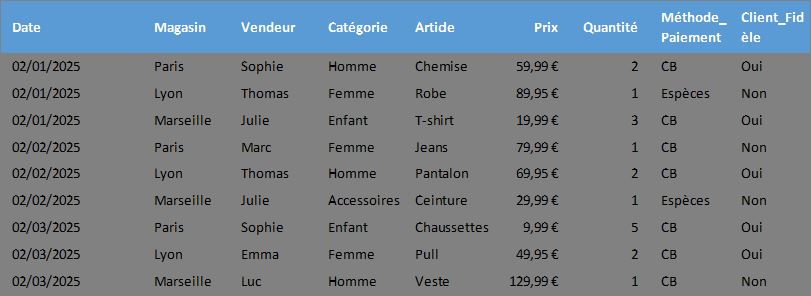
Pour illustrer ce tutoriel, nous allons utiliser le tableau suivant dans lequel sont compilées des données de ventes d'une chaîne de magasins de vêtements.
Ce tableau contient des informations détaillées sur les ventes réalisées dans différentes boutiques (Paris, Lyon, Marseille), par différents vendeurs, avec des catégories de produits variées (Homme, Femme, Enfant, Accessoires), et diverses méthodes de paiement. Nous y trouvons également des informations sur le statut de fidélité des clients.
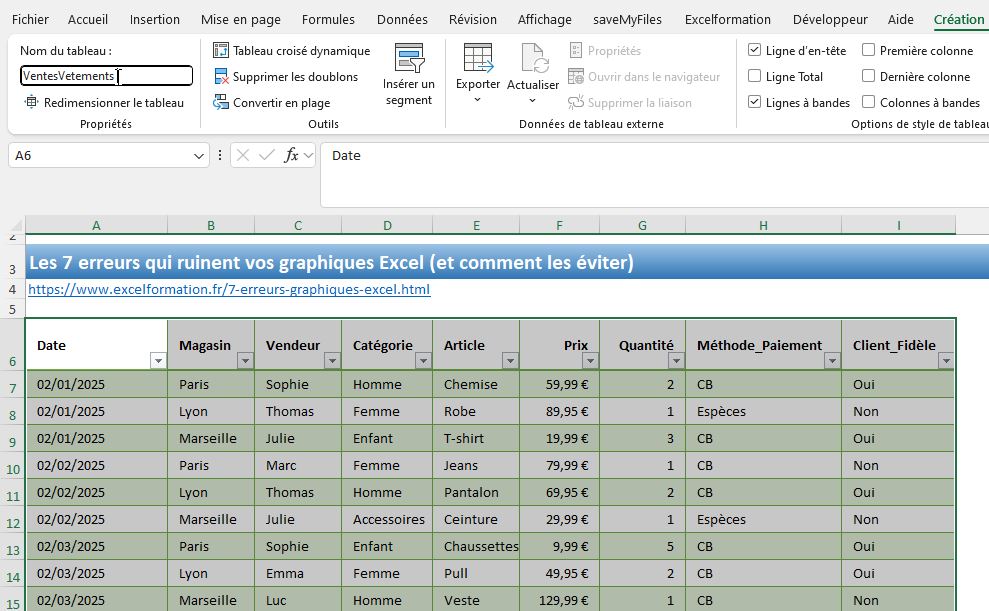
Pour commencer, il est important de le convertir en "Tableau Excel" pour faciliter la manipulation des données avec Python.
Pour cela, nous sélectionnons l'ensemble de nos données en cliquant sur l’une des cellules du tableau, puis en nous rendant dans l'onglet « Insertion » du ruban Excel, pour cliquer sur le bouton « Tableau ».
Une boîte de dialogue apparaît pour confirmer la plage de cellules sélectionnée. Nous vérifions que la case « Mon tableau comporte des en-têtes » est bien cochée, puis nous cliquons sur « OK ».
Par défaut, Excel attribue un nom générique à notre tableau (comme "Tableau1").
Pour faciliter notre travail avec Python, nous allons lui donner un nom plus explicite.
Pour cela, nous cliquons n'importe où dans notre tableau, puis nous allons dans l'onglet « Tableau » qui apparaît dans le ruban.
Dans la section « Propriétés », nous cliquons sur le champ « Nom du tableau » et nous remplaçons le nom par défaut par « VentesVetements ». Nous validons en appuyant sur la touche [Entrée].
Notre tableau est maintenant prêt à être analysé avec Python !
2. Introduction à Python dans Excel
2.1 Pourquoi utiliser Python dans Excel ?
L'intégration de Python dans Excel représente une avancée majeure dans le domaine de l'analyse de données.
Mais pourquoi cette nouveauté est-elle si révolutionnaire ?
Examinons les avantages clés que cette fonctionnalité nous apporte.
- Tout d'abord, Python offre une puissance d'analyse très supérieure aux formules Excel traditionnelles. Alors qu'Excel nous limite parfois à des formules complexes et imbriquées qui deviennent rapidement difficiles à maintenir, Python nous permet d'exprimer des analyses sophistiquées en quelques lignes de code claires et concises. Par exemple, une analyse de corrélation entre plusieurs variables qui nécessiterait de multiples formules dans Excel peut être réalisée en une seule ligne de code Python.
- Ensuite, Python excelle dans le traitement de grands volumes de données. Si nous travaillons avec des centaines de milliers, voire des millions de lignes, les formules Excel peuvent devenir lentes et instables. Python, avec ses bibliothèques optimisées comme pandas et numpy, peut traiter ces volumes de données bien plus efficacement.
- La création de visualisations avancées constitue un autre avantage majeur. Les graphiques Excel sont certes puissants, mais ils ont leurs limites en termes de personnalisation et de types de visualisations disponibles. Python, avec des bibliothèques comme matplotlib et seaborn, nous offre une liberté créative presque illimitée pour représenter nos données exactement comme nous le souhaitons.
- Enfin, Python dans Excel intègre déjà plusieurs bibliothèques spécialisées : pandas pour la manipulation de données, numpy pour les calculs mathématiques, matplotlib et seaborn pour les visualisations, et statsmodels pour les analyses statistiques avancées. Ces bibliothèques, reconnues et largement diffusées, sont désormais accessibles directement dans notre environnement Excel familier.
2.2 Comment activer et utiliser Python dans Excel
Maintenant que nous comprenons l'intérêt d'utiliser Python dans Excel, découvrons comment activer et utiliser cette fonctionnalité. Il existe trois méthodes principales pour accéder à l'éditeur Python dans Excel, et nous allons les explorer une par une.
- La première méthode consiste à passer par le ruban Excel. Nous nous rendons dans l'onglet « Formules » du ruban, puis nous recherchons le groupe « Python » (généralement situé à droite). Nous cliquons ensuite sur le bouton « Insérer Python ». Cette méthode est la plus visuelle et donc idéale pour les débutants qui découvrent la fonctionnalité.
- La deuxième méthode, plus rapide, utilise la saisie directe. Dans n'importe quelle cellule de notre feuille Excel, nous tapons simplement « =PY » puis nous appuyons sur la touche [Tab]. Excel reconnaît automatiquement que nous souhaitons utiliser Python et ouvre l'éditeur. Cette méthode est particulièrement pratique lorsque nous sommes déjà en train de travailler sur notre feuille et que nous voulons rapidement basculer vers Python.
- La troisième méthode, encore plus rapide pour les utilisateurs avancés, utilise un raccourci clavier. Nous appuyons simultanément sur les touches [Maj]+[Ctrl]+[Alt]+[P], et l'éditeur Python s'ouvre instantanément. Ce raccourci peut sembler complexe au premier abord, mais il devient très naturel avec la pratique.
Quelle que soit la méthode choisie, nous nous retrouvons face à l'interface de l'éditeur Python.
Un aspect important à comprendre est que notre code Python s'exécute dans un environnement connecté à notre feuille Excel.
Cela signifie que nous pouvons facilement accéder à nos données Excel depuis Python, et inversement, renvoyer les résultats de notre analyse Python vers Excel.
Pour exécuter notre code une fois qu'il est saisi, nous pouvons soit cliquer sur le bouton « Exécuter » en haut à droite de l'éditeur, soit utiliser le raccourci clavier [Ctrl]+[Entrée].
Les résultats de notre code apparaissent alors soit directement dans la cellule où nous avons inséré Python, soit dans une zone de résultats si nous avons généré des visualisations ou des tableaux.
Maintenant que nous savons comment accéder à l'éditeur Python, passons à la pratique et commençons à manipuler nos données de ventes !
3. Manipulation et analyse basique des données
3.1 Charger des données Excel dans Python
La première étape de notre analyse consiste à charger nos données Excel dans un format que Python peut manipuler efficacement.
Pour cela, nous utilisons la bibliothèque pandas, qui permet de créer des structures de données appelées « DataFrames » - essentiellement des tableaux intelligents qui offrent de nombreuses fonctionnalités d'analyse.
Commençons par créer un DataFrame à partir de notre tableau Excel. Nous ouvrons l'éditeur Python en utilisant l'une des méthodes que nous avons apprises (par exemple, en tapant « =PY » dans une cellule puis en appuyant sur [Tab]).
Dans l'éditeur, nous saisissons le code suivant :
df=xl("VentesVetements[#Tout]", headers=True)
df
Ce code très simple fait deux choses importantes. D'abord, il accède à notre tableau Excel nommé « VentesVetements » grâce à la fonction « xl », en prenant également les en-têtes.
Ensuite, il stocke ce tableau dans une variable nommée `df` (pour DataFrame, selon la convention en analyse de données).
La deuxième ligne affiche simplement le contenu de notre DataFrame.
Nous appuyons sur [Ctrl]+[Entrée] pour exécuter ce code.
Nous voyons alors apparaître notre tableau de données dans l'éditeur Python, mais sous forme de DataFrame pandas.
Si ce n’est pas directement le cas, utilisez le raccourci clavier [Maj]+[Ctrl]+[Alt]+[M].
Cette transformation peut sembler mineure visuellement, mais elle nous donne accès à toutes les fonctionnalités puissantes de pandas.
Pour explorer notre DataFrame, nous pouvons utiliser diverses fonctions.
Par exemple, pour voir les premières lignes de nos données, nous pouvons utiliser la fonction `head()`.
Nous ajoutons la ligne suivante à notre code :
df.head(3)
Après avoir exécuté cette ligne avec [Ctrl]+[Entrée], nous voyons les trois premières lignes de notre tableau. C'est très utile pour vérifier rapidement la structure de nos données sans avoir à afficher l'intégralité du tableau, surtout lorsque nous travaillons avec de grands volumes de données.
De même, pour voir les dernières lignes, nous utilisons la fonction `tail()` :
df.tail(3)
Ces fonctions `head()` et `tail()` sont particulièrement utiles lorsque nous travaillons avec de grands tableaux comportant des milliers ou des millions de lignes, car elles nous permettent d'avoir un aperçu rapide des données sans surcharger notre écran ou notre mémoire.
Une astuce importante : si nous ne spécifions pas de nombre entre parenthèses, comme dans `df.head()` ou `df.tail()`, pandas affiche par défaut 5 lignes.
Mais nous pouvons personnaliser ce nombre selon nos besoins, comme nous l'avons fait en demandant seulement 3 lignes.
3.2 Statistiques descriptives
Maintenant que nos données sont chargées dans un DataFrame pandas, nous pouvons facilement obtenir des statistiques descriptives qui nous donneront un aperçu global de nos données de ventes.
La fonction `describe()` est l'un des outils les plus puissants de pandas pour obtenir rapidement des statistiques sur nos données numériques. Ajoutons la ligne suivante à notre code Python :
df.describe()
Après exécution, nous obtenons un tableau de statistiques pour toutes les colonnes numériques de notre DataFrame (dans notre cas, principalement « Prix » et « Quantité »). Ce tableau inclut :
- Le nombre de valeurs (count)
- La moyenne (mean)
- L'écart-type (std)
- La valeur minimale (min)
- Les quartiles (25%, 50% ou médiane, 75%)
- La valeur maximale (max)
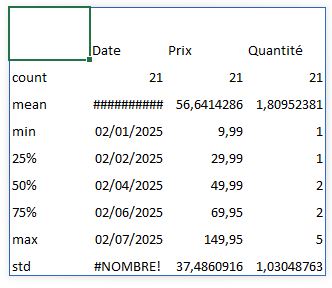
Ces statistiques nous donnent immédiatement des informations précieuses.
Par exemple, nous pouvons voir que le prix moyen des articles vendus est d'environ 56,64 € (moyenne de la colonne « Prix »), avec un prix minimum de 9,99 € (probablement les chaussettes) et un maximum de 149,95 € (le manteau).
De même, nous constatons que la quantité moyenne vendue par transaction est d'environ 1,8 unités.
Pour les colonnes catégorielles comme « Magasin », « Vendeur » ou « Catégorie », la fonction `describe()` standard n'est pas aussi informative.
Heureusement, nous pouvons obtenir des statistiques spécifiques pour ces colonnes en les sélectionnant individuellement. Par exemple :
df["Magasin"].describe()

Cette commande nous donne :
- Le nombre de valeurs (count)
- Le nombre de valeurs uniques (unique)
- La valeur la plus fréquente (top)
- Sa fréquence (freq)
Nous pouvons aussi utiliser `describe()` sur plusieurs colonnes à la fois en les sélectionnant dans une liste :
df[["Magasin", "Catégorie"]].describe()
3.3 Calculs et agrégations
Passons maintenant à des analyses plus avancées avec des calculs et des agrégations qui nous permettront d'extraire des indicateurs commerciaux de nos données de ventes.
Une première analyse essentielle consiste à calculer le montant total de chaque vente (prix unitaire × quantité), puis à analyser ces montants. Ajoutons le code suivant à notre éditeur Python :
df=xl("VentesVetements[#Tout]", headers=True)
df["Montant"]=df["Prix"]*df["Quantité"]
df
Nous avons créé une nouvelle colonne « Montant » dans notre DataFrame qui contient le montant total de chaque vente.
Nous pouvons maintenant calculer le chiffre d'affaires total de notre période d'analyse :
df=xl("VentesVetements[#Tout]", headers=True)
df["Montant"]=df["Prix"]*df["Quantité"]
np.sum(df["Montant"])
Ici nous utilisons numpy via la commande « np », sans que nous n’ayons besoin de l’importer, car celui-ci est déjà inclus dans la session Python d’Excel.
Le résultat nous indique le chiffre d'affaires total généré par toutes les ventes de notre tableau.
Nous aurions pu obtenir le même résultat avec `df["Montant"].sum()`, mais l'utilisation de numpy (`np.sum()`) peut être plus efficace pour de grands volumes de données.
L'une des fonctionnalités les plus puissantes de pandas est la fonction `groupby()`, qui nous permet d'analyser nos données par catégories. Par exemple, pour analyser les ventes par magasin :
df.groupby("Magasin")["Montant"].sum()
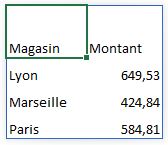
Cette commande nous donne le chiffre d'affaires total pour chaque magasin (Paris, Lyon, Marseille). Nous pouvons immédiatement voir quel magasin génère le plus de revenus.
Nous pouvons également faire des analyses plus complexes en groupant par plusieurs colonnes. Par exemple :
df.groupby(["Magasin", "Catégorie"])["Montant"].sum()

Ce résultat nous montre le chiffre d'affaires pour chaque combinaison de magasin et de catégorie. Nous pouvons ainsi identifier quelles catégories de produits se vendent le mieux dans chaque magasin, une information précieuse pour optimiser notre assortiment.
Une autre analyse intéressante consiste à comparer les ventes entre clients fidèles et non fidèles :
df.groupby("Client_Fidèle")["Montant"].sum()
Nous pouvons aussi calculer des moyennes au lieu des sommes, par exemple pour voir le panier moyen par méthode de paiement :
df.groupby("Client_Fidèle")["Montant"].mean()
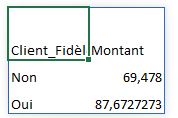
Un aspect puissant de pandas est la possibilité de combiner plusieurs agrégations.
Par exemple, pour voir à la fois la somme, la moyenne, le minimum et le maximum des ventes par vendeur :
df.groupby("Client_Fidèle")["Montant"].agg(["sum", "mean", "min", "max"])

Cette commande nous donne un tableau complet avec, pour chaque vendeur, le chiffre d'affaires total, le panier moyen, ainsi que les montants minimum et maximum de ses ventes.
Nous pouvons ainsi identifier nos vendeurs les plus performants et comprendre leurs patterns de vente.
4. Visualisation des données avec Python
4.1 Graphiques de corrélation
La visualisation des données est un aspect où Python excelle particulièrement.
Commençons par explorer la corrélation entre nos variables numériques à l'aide de matrices de corrélation et de heatmaps.
Pour créer une matrice de corrélation, nous sélectionnons d'abord nos colonnes numériques et nous calculons leur corrélation avec la fonction `corr()` :
df=xl("VentesVetements[#Tout]", headers=True)
df["Montant"]=df["Prix"]*df["Quantité"]
df_num = df[["Prix", "Quantité", "Montant"]]
Après exécution, nous obtenons une matrice qui montre les coefficients de corrélation entre nos variables numériques. Ces coefficients varient de -1 à 1, où 1 indique une corrélation positive parfaite, -1 une corrélation négative parfaite, et 0 l'absence de corrélation.
Pour rendre cette matrice plus lisible visuellement, nous pouvons créer une heatmap (carte de chaleur) en utilisant la bibliothèque seaborn :
df_num = df[["Prix", "Quantité", "Montant"]]
correlation_df = df_num.corr()
sns.heatmap(correlation_df, annot=True, cmap="Blues")
Cette commande génère une visualisation colorée où l'intensité de la couleur représente la force de la corrélation, et les valeurs numériques sont affichées directement sur la carte.
Le paramètre `cmap="Blues"` spécifie la palette de couleurs (ici, des nuances de bleu).

Ici, la matrice est toute petite, car la taille s’adapte à la cellule.
Pour l’agrandir, il suffit de fusionner une plage de plusieurs cellules :
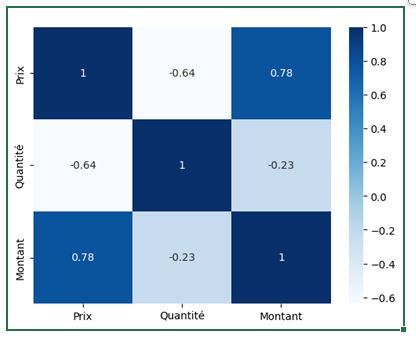
En analysant cette heatmap, nous pouvons observer plusieurs tendances intéressantes :
- Une forte corrélation positive entre le "Montant" et le "Prix", ce qui est logique puisque le montant dépend directement du prix.
- Une corrélation plus faible entre le "Montant" et la "Quantité", suggérant que les variations de prix influencent davantage le montant total que les variations de quantité.
- Une corrélation négative entre "Prix" et "Quantité", indiquant que les articles plus chers tendent à être achetés en plus petites quantités.
Nous pouvons personnaliser davantage notre heatmap en ajoutant des options :
correlation_df = df_num.corr()
sns.heatmap(correlation_df, annot=True, cmap="coolwarm")
plt.title("Matrice de corrélation des variables de vente")
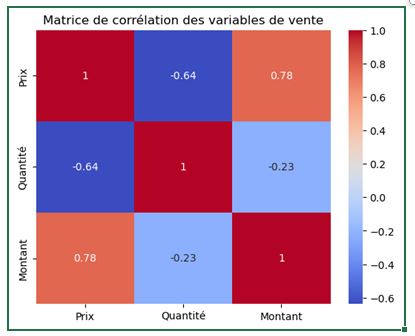
Dans cette version améliorée, nous avons changé la palette de couleurs pour "coolwarm" (bleu pour les corrélations négatives, rouge pour les positives) et ajouté un titre explicatif.
4.2 Graphiques de distribution
Pour mieux comprendre la distribution de nos variables numériques, nous pouvons créer différents types de graphiques de distribution.
Commençons par un histogramme simple pour analyser la distribution des prix :
correlation_df = df_num.corr()
sns.distplot(df["Prix"], bins=8, kde=False)
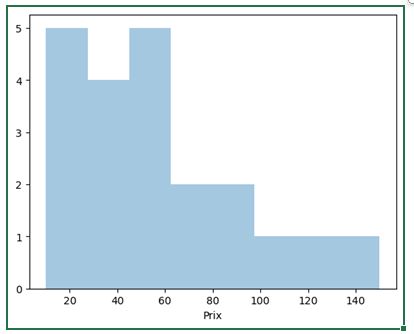
Cet histogramme nous montre combien d'articles se situent dans chaque tranche de prix. Le paramètre `bins=8` divise notre plage de prix en 8 intervalles égaux.
L'option `kde=False` désactive la ligne de densité qui est affichée par défaut.
Nous pouvons également créer des boxplots (boîtes à moustaches) pour comparer la distribution des prix par catégorie :
sns.boxplot(x="Catégorie", y="Prix", data=df)
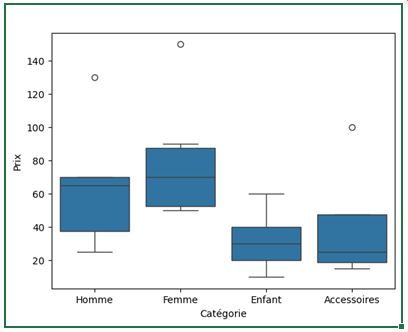
Nous pouvons immédiatement voir que la catégorie "Homme" a une plus grande variabilité de prix que la catégorie "Enfant", par exemple, ou que les "Accessoires" ont généralement des prix plus bas que les autres catégories.